
Data Modelling & Semantics
Introduction to Data Modelling & Semantics
IOTICS believes that semantically described data is the only way to truly, flexibly and consistently interoperate data across domains and companies, for both humans and machines.
We believe that the data owner should be empowered to
- describe and structure their data as it is meaningful to them.
- make their data easy and unambiguous for others to understand.
Only by using Semantic Web Technologies, specially in the IOTICS context, we can ensure that the data owner remains in control of their data and their knowledge whilst still being able to link and refer to others' knowledge, rather than be exclusively forced to adapt to an external standard.
How can Semantics help you?
Interoperate across sectors
Define and share your understanding of your world with others in a different world, without a common standard.
Evolve the standard
Having one single global standard is close to impossible, time-consuming, and unnecessary. Why wait?
Serves humans and machines
Semantically described data is the prerequisite for machine-readability and machine-actionability. Only through rich semantic descriptions, a machine will know the difference between a (goldfish) tank and a (military) tank.
Find data via concepts
Find the right data - data you know exists, data that is linked to it, or inferred to be the same.
Information inventory
Structure and connect all kinds of data, analyse relationships and detect patterns. Think Knowledge Graphs built on Linked Data.
Extensibility & no vendor lock-in
Based on RDF and W3C standards, data can be referenced, understood and interpreted by any other tool. Extend, export and reuse.
Terms & Definitions
| Term | Definition |
|---|---|
| Semantics | The study of reference, meaning and truth. For humans, this means a more consistent understanding across domains, companies and languages. For machines, semantically described data is the prerequisite for machine-readability and machine-actionability. |
| Ontology | A list of concepts and categories in a subject area that shows their properties and the relations between them. E.g.: schema.org |
| Metadata | Data that provides meaningful information about other data. |
| Data | Actual data, such as a data feed, dataset, and status updates. |
| Knowledge Graph | A knowledge base that uses a graph-structured data model or topology to integrate data. |
| Triples | Subject (Twin), Predicate (Property name), Object (Value of property). |
| RDF, Turtle, JsonLD, SPARQL, SHACL | Languages and frameworks to implement and work with semantics. |
Prerequisites
As with any modelling or architecture exercise, it's important to understand and define the business case as well as the use case, objectives and scope, ahead of time. This will ensure that the final output answers all the requirements.
How to model and semantically describe your data
Data modelling is usually not a linear process, but rather an agile loop from
version 1 --> adapt --> version 2 --> adapt --> version 3 --> adapt etc, until the model to be used emerges.
There are 2 broad approaches to data modelling:
Option 1: Model your asset, then find the data you need.
Option 2: Gather the data, then model the asset accordingly.
In IOTICS we encourage Option 1 whenever possible as it is the fastest approach to get you started. Even without data or with partially available data, by synthesising the missing data.
Modelling your data
Decide the list of twins and data values
Depending on your use case and your experience with data modelling, deciding on what the twin should represent may be obvious or fuzzy at best.
We've drafted the below checklist to help you navigate what should be a twin, and what shouldn't.
What is your business or use case centred around?
A specific (group of) asset(s), people or something else?
Consider that:
- A twin can be of anything: an asset, a person or a concept. A manufacturer may have twins of its equipment or final products, a care home may have twins of its residents, and a bank may have twins of mortgages.
Should real assets data be twins or properties?
If you have many different types of twins, or if one of your twins doesn't receive any data from an external data source, consider that:
- Albeit twins can be of anything, not everything needs to be a twin. Instead, it could be listed or referred to as a property of another twin. Too many different types of twins may be over-complicating your use case or add more work than you need. And if your requirements change over time, you can create a Digital Twin once it becomes necessary.
- To show how something relates to something else, a property may be enough. For example, each car manufacturer may not need their own twin, but can rather be referred to as a property "manufacturer" on the Digital Twin of each car.
Do you need more than one twin for each real thing?
Consider that:
- There is no need to have to be a 1:1 relationship between each real and digital thing.
- For example, consider having one Digital Twin with all the granular data for internal consumption, and another Digital Twin with anonymised or less granular data for sharing with a third party.
Similarly, you could have one twin of the real asset and one of a simulated one. - Multiple twins which relate to the same asset, can be linked to form a graph.
When do you have enough metadata properties per twin?
Consider that:
- The list of data values doesn't have to be exhaustive per Digital Twin. Properties can be changed, added and removed at any point. It may be more important to you to get started reasonably quickly and iterate, rather than get it perfectly right from the start.
- You don't need to have access to the actual data for modelling purposes, nor later when creating the twin - the property could just be left blank to be filled in later.
The outcome of this section may look like the following:
| Twin 1 | Twin 2 | |
|---|---|---|
| Data values | A B C D E | A B G H I |
Decide Metadata vs Data
The distinction between metadata and data is not always obvious.
We've created the following table as a high-level guidance. If in doubt or need advice on how to proceed, contact us through IOTICS Support and we're happy to help.
| Metadata | Data | |
|---|---|---|
| Definition | Data that provides meaningful information about other data. | Actual data, such as a data feed, dataset, status updates. |
| In practice, it represents | Information about the asset. The asset itself, its data feeds and inputs are all described using properties. The asset’s feeds and inputs are also described using respective properties. | It can represent information about the internal status of the real asset or status changes, propagated as events. |
| In IOTICS, it is modelled as | metadata properties. | data feed = data stream of changes or events (push). |
| Data Frequency | Static or infrequent updates. | Streaming data at regular or irregular event-driven intervals. |
| Security and Visibility | Metadata properties are by default invisible to other Hosts and therefore they can't be found and seen by any user of any IOTICSpace. However they can be set to visible to some or all IOTICSpaces. | Access to data feeds can be set at a granular level by the data owner, by either allowing all, none or a select group of IOTICSpaces to access the data. |
| Search | Metadata properties are searchable. | Data in data feeds cannot be searched. |
| IOTICS quirks | Location should be made a metadata property for the map to work. A URL can be a metadata property to link to external resources, such as other twins, datasets on the web, etc. |
The outcome of this section may look like the following:
| Twin 1 | Twin 2 | |
|---|---|---|
| Metadata | A B C | A B |
| Data | D E | G |
| Not sure | H I |
IOTICS Semantic Web Stack
The Semantic Web Technology Stack refers to a set of standards and protocols, managed by W3C, designed to enhance the ability to understand and process information.
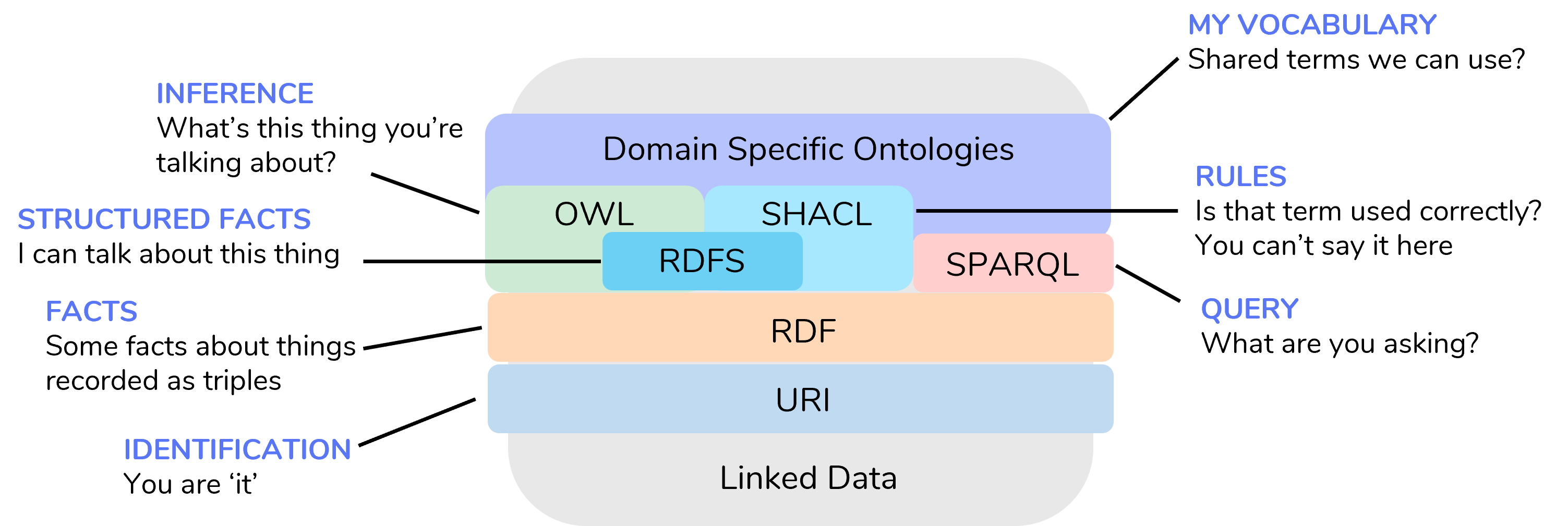
At its core, you’ll find RDF (Resource Description Framework), a system for representing data relationships. RDF builds on the URI standard, which allows unique identification of resources on the web.
Ontologies provide a shared understanding of concepts, and they are built using RDF and OWL, while SPARQL enables querying linked data.
Linked Data principles promote interconnecting diverse datasets. These technologies collectively empower machines to comprehend and infer meaning from unstructured or structured data.
Modelling Metadata, Feeds and Inputs
When creating a virtual representation of anything in the real world, it's essential to start with their metadata, feeds, and inputs.
The metadata of the real-world entity captures the properties describing the entity’s physical characteristics, like its size, location, and manufacturer. These are transformed into triples, where the entity ID serves as the subject, and predicates are linked to standard ontologies like schema.org or SAREF. For instance, an entity’s length could be linked to a hasLenght predicate in the ontology.
Feeds represent the entity’s status changes over time, expressed as triples detailing stream characteristics (e.g., frequency, SLA). These feeds include data points, each with a label, a value (number, timestamp, etc.), and an optional unit of measure.
Modelling Behaviour
Defining the behaviour of the virtual asset involves creating the logic for managing updates to metadata, data and handling inputs. This logic is programmed in an agent application we call Connector.
The connector needs to be integrated with the asset's operations and must be programmed to map the asset to the metadata using the appropriate ontology, based on predefined standards or custom extensions.
For metadata updates, relevant properties are mapped and managed using predicates.
For status updates, the connector identifies what data needs to be included in the feed payload and how to structure it based on the description provided as payload metadata. The mapping process ensures that real-world changes are accurately represented in the virtual model. Inputs, representing controls, are also structured with labels and values. Upon receiving an input payload, the system relays the information to the asset, bridging the gap between the virtual and physical domains.
It is important to highlight that the virtual representation of the asset doesn’t have to be a 1:1 mapping with the virtual, in fact:
- Not all asset’s specifications need to be mapped as properties and some properties can be synthesised by the connector as required
- Not all internal status changes need to be mapped as feeds, and some feeds may be synthesised as appropriate
- Not all controls have to be mapped as inputs, and some inputs may be synthesised as appropriate, for example, to control the behaviour of the connector itself.
Modelling identity
Managing the identity of the virtual representation involves leveraging cryptographic tools for secure identification.
This ensures that the virtual asset can be uniquely identified and trusted. Cryptographic techniques such as digital signatures or certificates can be used to authenticate the virtual representation.
This identity management ensures that the virtual asset's data, metadata, and interactions are secure and verifiable, maintaining the integrity of the overall system. In IOTICS, refer to the identity library and the DID specification.
How to use it
Search
The ability to perform search and query operations on twins' metadata, modelled using semantics, is a valuable feature that enhances the management and retrieval of information within the IOTICSpace. These search operations allow you to quickly locate relevant twins based on specific criteria.
Let’s use the description of this Fiat 500 to understand the types of search.
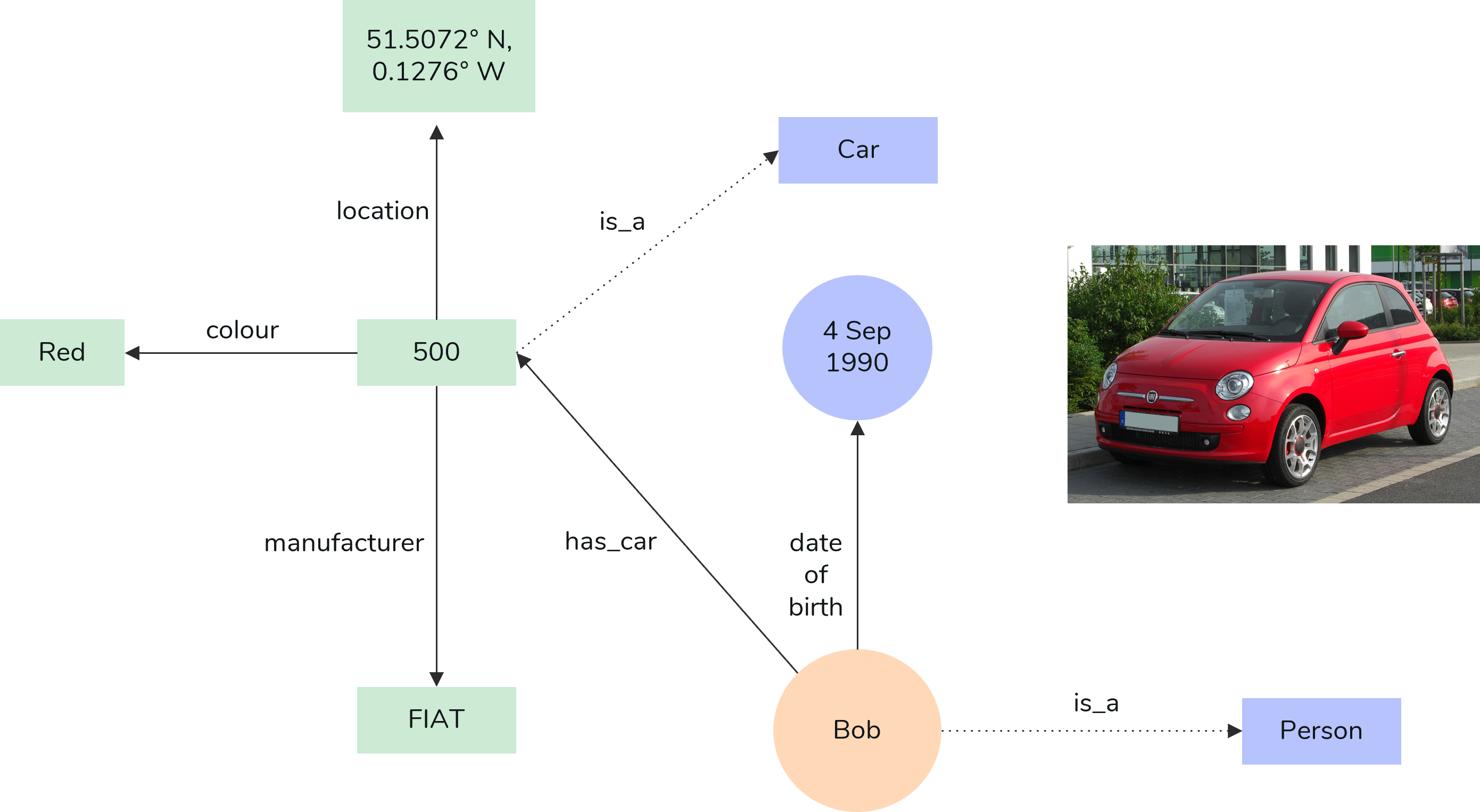
- Property Search
You want to find all the twins of FIAT cars.
All twins manufactured by FIAT will have the ‘make’ property set to FIAT, once you look for this specific property, the search will return all twins that match this criterion.
This is particularly useful when you're focusing on a specific attribute that many twins share, allowing you to efficiently filter and access the relevant information. You can submit more than one property and retrieve all twins that match all the properties in the request. - Text Search
You want to find all the twins of the cars you own.
In this case, the car's ownership is included in their metadata labels or comments, therefore you can text search.
If you search for the car I own, it will return twins that include this text in their labels, comments, or other relevant text fields.
This is a versatile way to find twins based on descriptive information, regardless of the specific property names. Think about a kind of Google Search for twins. - Location Search
You want to know where your car is.
Location-based search is another powerful capability.
It enables you to find twins within a specified geographic area. In this case, if you're looking for twins within a 1km radius of the coordinates (latitude 37.2, longitude 0.13), you'll retrieve all twins located in that vicinity.
This is especially handy for scenarios where you need to manage assets across physical locations and perform localised operations.
Query
- Aggregations and Filtering
SPARQL enables you to perform aggregations on the metadata of twins, providing insights into patterns and trends across the network.
For instance, you can use SPARQL to count how many twins represent cars of the model 500.
This aggregation offers a quick overview of the number of such twins within the entire system. - Complex Classification
The flexibility of SPARQL allows you to classify and categorise twins based on multiple criteria.
You can find all twins that are either cars or bikes, essentially creating a dynamic classification of assets.
This helps in grouping and managing different types of assets more efficiently. - Exclusion and Filtering
SPARQL also supports exclusion and filtering.
For example, you can query to find all twins that are not weather stations.
This feature aids in identifying specific types of assets while excluding others, streamlining your search for relevant information.
This feature can also help in addressing data quality issues. - Data Sharing and Compatibility
SPARQL's ability to identify twins that share specific characteristics is valuable.
For instance, querying for twins that have a feed sharing temperatures in Celsius highlights assets that share a common data attribute.
This can be crucial for data sharing, analysis, and ensuring compatibility in applications that require certain data formats.
With SPARQL as the querying language for the federated knowledge graph, users gain a powerful tool to explore, analyse, and gain insights from the vast amount of semantically modelled metadata. The ability to perform these operations across a network of IOTICSpaces enhances the understanding of the interconnected virtual representations, ultimately aiding in decision-making, optimisation, and effective management of assets.
Updated 9 months ago